ZoomPhant using a streaming processing lanuage to process the logs, and a log processing statement may contain following parts:
- Log Filtering: Using labels or keywords to reduce the size of logs to be processed
- Log Processing: Processing the filtered logs to do conversion / analyzing or grouping, etc.
- Log Presenting: Decides how to present the processed logs, e.g. show as pure logs or a diagram in given shapes, etc.
For a quick reference, you can refer to Log_Query_CheatSheet
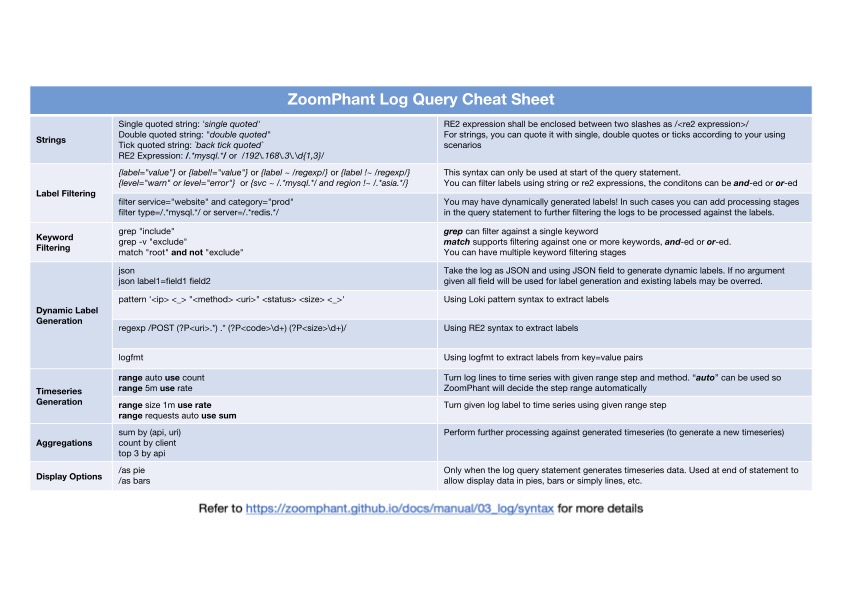{kind=link}
Syntax
ZoomPhant Log Query Language is a staged stream processing language, the statement is separated by pipe ‘|’ into different processing stage and having an overall syntax as follows
{ streamFiltering } keywordsFiltering | processorFunc1 [args...] | processorFunc2 [args...] /as displayType
In above stage, the first stage is a filtering stage (more details below), this stage is optional by strongly recommended, followed by one or more processing stage, and could be ended with an optinal display specification.
Before explaining the details of the processing functions, let’s see how strings could be expressed in the syntax.
Strings are widely used as label value, keyword and processor arguments, etc. We support different ways to express a string, which can bring convenience for users in different situations.
Double Quoted Strings
This is the most common way to express strings: quote the string in double quotes, and in the string there shall have no double quote.
Below are examples of valid double quoted strings.
"error"
"Error"
"He's great"
"/api/ping"
And it is illegal to have a double quote in the double quoted string:
"invalid "double quote""
Single Quoted Strings
We can use single quoted string to express strings with double quotes, but in single quoted strings there shall be no single quote.
‘Error’
‘The "test" string is OK'
'/api/ping'
Single quote is not allowed in single quoted strings:
'invalid 'single quote''
Tick Quoted Strings
In case you need to use both single and double quotes in your string, you can use the tick quoted strings, as shown below:
`Error`
`The "double quoted" string and 'single quoted' string`
`/api/ping`
But tick shall not show up in tick quoted strings:
`Illegal `back quote``
RE2 Expression
RE2 expression is a special string, we use slash ‘/’ to enclose such strings, as shown below
/.*mysql.*/
/192\.168\.3\.\d{1,3}/
For more information about RE2 syntax, you can refer to https://github.com/google/re2/wiki/Syntax.
Log Filtering
Log volumes could be huge, so when querying and processing logs, we shall filter those logs that we want to process first to improve the efficency.
There are two types of filtering:
- Log Stream Filtering: A log stream is identified by the label set, so this kind of filtering will try to filter the label values to select the correct stream to process.
- Keyword Fitlering: Keyword filtering can be used to further filter log lines with certain keywords.
As said above, each log query statement shall try to use filters to reduce the volume of queried logs to improve the performance.
Log Stream Filtering
As said above, log stream filtering filters against the log labels. The basic syntax for filtering a label is as follows:
labelName <Operator> labelValue
Depends on the operator, the labelValue could be
- Double, single or tick quoted strings
- RE2 regular expressions enclosed by slashes
Here the operator could be:
- = The label value matches the given string exactly
- != The label value doesn’t exactly match the given string
- ~ The label value matches the given RE2 expression
- !~ The label value doesn’t match the given RE2 expression
Two or more label filters could be and-ed or or-ed together to create a complex log stream filter against multiple labels:
_instanceName ~ "prod.*" and _category="database"
Keyword Filtering
Keywords filtering will be used on log lines directly. Used with log stream filtering, it can further reduce the volume of the logs to be queried and processed.
Keywords can be any strings in double, single or tick quotes, it can also be a RE2 expression in certain situations. Following are valid keywords:
- Single quoted string keyword: ‘keyword’
- Double quoted string keyword: “keyword”
- Keyword in RE2 expression: /key?word/
Like label filters, we can use and, or and not keywords to create complex keyword filtering against multiple keyworkds, for example:
"Error" or "Exception"
or
/.*mysql.*/ and not "database"
Using Filtering
When using filtering, we support two ways to specify label and keyword filters
- Using Literals: this can only be used on start of query statement
- Using Functions: We can add one or more processing stages using filtering functions
Using Literals
Filtering literals can only be used at start of a query statement, we would recommend user to always starts with filtering literals to improve log querying and processing.
The syntax for filtering literals is as follows:
{ <stream filtering> } <keyword filtering>
In this syntax, the filtering contains two optional parts
- the stream filters, surounded by brackets
- followed by optional keyword filters
Following are some examples using above syntax
{_source~/.*prod-\d+/ and _cagetory="webserver"} "Error" or "Warn"
{level="error" or level="warn"}
"/api/ping" and "error"
Using Functions
Filering literals can only be used at start of query statement. To make your query statement easier to understand, you can use filtering functions, which can appear at different stages. Filtering functions has following syntax
funcName filterExpression
We will have more details for supported filtering functions later, for now we can see below examples for using filtering functions
grep "Error" | grep -v "website"
match "Error" or "Warn" | filter _category="database"
filter _source!~/.*mysql.*/ and _level="error" | grep -v "test"
Log Processing & Displaying
After we have filtered out the logs we want to process, we may need to further processing the logs like extracting certain information from log lines, counting the lines and find patterns about appearances of certain keywords, etc.
We use functions to do such processing, and the processed result could be presented in different formats using the displaying options.
Log Functions
We call the each processing method a function, and according to the type of processing, we can group the functions as:
- Log Filtering Functions: Used to filter logs using labels or keywords to achieve the same purpose as using filtering literals mentioned above.
- Log Expanding Functions: Used to generate dynamic labels, converting log lines, extracting information from log labels or log lines, etc.
- Log Processing Functions: Used to create timeseries from log streams and do analyzing / aggregations on the timeseries.
Log Filtering Functions
We support following special functions to filter against log labels (streams) and log lines (keywords)
- grep: Used to filter log lines against one keyword, an optional -v option could be used to inverse the effect, as shown in below examples
- grep “12345”
- Finding all the loglines that contains 12345
- grep -v 12345
- Finding all the logs that not contains 12345
- grep “12345”
- match: Used to filter log lines against multiple keywords by using keyword filtering expressions. User can use brackets to change the default processing order, for example:
- match (“Failed” or “failed”) and /192.168.\d{1,3}.\d{1,3}/
- Find all log lines containing one of “Failed” and “failed”, and also with a matching IP address
- match “error” and “network”
- Find all lines containing both “error” and “network”
- match (“Failed” or “failed”) and /192.168.\d{1,3}.\d{1,3}/
- filter: Used to filter log streams or log labels. Like above match function, it expects user to provide a label filtering expression as arguments, for example
- filter service = “finance”
- Filter all log streams with a service label with value “finance”
- filter location != “Canada”
- Filter all log streams with a location label not equal to “Canada”
- filter name ~ /Instance .*/ and _category = “website”
- Filter log streams with name label matching given RE2 exrepssion and _category label set to “website”
- filter service = “finance”
Log Expanding Functions
Those functions can help convert log stream by expanding labels or cnverting the log lines. For now we support following functions
- json: Take the log line as valid JSON and extract the fields in this JSON as labels. Existing labels may be overwritten by this operation. For example
- json
- with out argument, each field will be generated as a label
- json location, size
- Extract the location and size field to create new location and size labels
- json
- pattern: This is the same as the Loki pattern processing function, which can be used to quickly extract pattern form log lines and generate new labels. It would expect a pattern as argument and use it to match the log lines, using blank space as separator. You can give a name using <labelNamne> to generate a label with the matching part or special <_> to ignore that part. For example,
- pattern ‘<ip> - - <_> "\<method\> \<uri\> <_>" \<status\> \<size\> <_>'
- Match a log line, with the first part used to generate ip, method, uri, status and size labels
- pattern ‘<ip> - - <_> "\<method\> \<uri\> <_>" \<status\> \<size\> <_>'
- regexp: Using RE2 syntax to matching named pattern and using the name to generate labels
- regexp /POST (?P
.*) .* (?P \d+) (?P\d+)/ - Matching the url, code and size part to generate labels accordingly
- regexp /POST (?P
- logfmt: Take the log lines as following the logfmt format and convert the key=value pairs as labels. You can visit following link for more information
- https://www.brandur.org/logfmt
More log expanding functions will be supported in the future.
Log Processing Functions
Log lines are hard to extract useful information and to display. We can use log processing functions to vectorize the loglines as time series to identify patterns and presenting to customers.
To processing the log lines for above purpose, we need to through following steps
- Vectorize logs: This is the first step and we would generate the initial timeseries from the log lines which can be further processed and displayed
- Timeseries processing: We can using various aggregation and processing functions to process the generated timeseries.
- Data presenting: With the final data, we can shall it in a way easier for user to understand the data
Log Vectorizing Function
ZoomPhant support a range function to vectorize the log lines or log labels in given steps:
range <vecorizingRange or step> use convertingFunc [<convertingParam1> ...]
range <labelName> <vecorizingRange or step> use convertingFunc [<convertingParam1> ...] [without|by (labelSet)]
In above syntax
- the first is used to vectorize against log lines
- the second is used to vectorize against given labelName
- When aggregate against labels, a labelSet can be provided to filter or aggregation log streams
In both cases,
- vecorizingRange or step is used to given the a time range to vectorize the log, it is given in format like 5m, 1h or auto so ZoomPhant can automatically decide the value.
- convertingFunc is a name to decide what kind of function we can use to do the vectorizization, as shown below
Converting Function for Log Lines
If we try to vectorize against the log lines, we can using following converting functions
- rate: Number of log lines generated per second every given time range (speed)
- count: Number of log lines generated in given time range
- bytes_rate: Number of bytes per second generated every given time range (speed)
- bytes_count: Number of bytes generated in given time range
- absent: if any logs generated every given time range. If yes a vector with value 1 is returned, otherwise an empty vector is returned
Converting Function for Log Labels
To vectorize against a given label following function could be used
- rate:Taken the label value as a number, the change rate of the accumulated sum in given time range
- sum:Taken the label value as a number, the accumulated sum in given time range
- avg:Taken the label value as a number, the average value in given time range
- max:Taken the label value as a number, the maximum value in given time range
- min:Taken the label value as a number, the minimum value in given time range
- first:Taken the label value as a number, the first non-null value in given time range
- last:Taken the label value as a number, the last non-null value in given time range
- stdvar:Taken the label value as a number, the standard variation value in given time range
- stddev:Taken the label value as a number, the standard deviation value in given time range
- quantile:Taken the label value as a number, the proportion of values above given percentile. The percentile is given as a number like 90 as the first argument and if missing taken as 90 percentile
- absent:If no value in gime time range, return an empty vector, otherwise an vector with value 1 is returned
Log Processing Functions
Once we have vectorized timeseries data, we can further processing the timeseries using log processing functions in following syntax
<funcName> [<funcParam1> ...] (without|by) (labelSet)
So the log processing functions can further filter / aggregation the timeseries using given label set, and following functions are supported
- sum: Calculate theaccumulated value aggregated by given label set
- avg: Calculate average value aggregated by given label set
- min: Get the minimum value aggregated by given label set
- max: Get maximum value aggregated by given label set
- stdvar: Calculate the standard variation aggregated by given label set
- stddev: Calculate the standard deviation aggregated by given label set
- count: Count the number of streams aggregated by the given label set
- top: Return the top N series aggregated by the given labelset, N is given as the first param, default to 3 if not given
- bottom: Return the bottom N series aggregated by the given labelset, N is given as the first param, default to 3 if not given
Log Display Options
By default we display log data as just log lines and timeseries data as colored lines. User can use the display option to override the display if it applies
/as <displayOption>
Here, displayOption could be one of following
- line or lines: Display the timeseries data as lines, this is the default
- pie or pies: Display the timeseries as pie diagrams
- bar or bars: Display the timeseries as bar diagrams
- area or areas: Display the timeseries as areas.
- stack or stacks: Display the timeseries as stacked areas.